In this small project we made a classification system for emails into spam and regular emails. We used relatively simple methods for converting the text into vectors and classification, however it turned out to be rather effective. Even with these very simple methods it is possible to get an accuracy > 95%. Although this particular problem is not the most difficult, as we are only concerned with a binary classification.
The general outline was to build a huge sparse matrix matrix based on the counts of words in each document (email), think something like $n_{docs} \times n_{words}$ of the order $4000 \times 25000$.
Using the TF-IDF measure downweighs the longer documents.
We get a large matrix that looks something like this.
| word 1 | word 2 | … | … | word n | |
|---|---|---|---|---|---|
| Document 1 | tf-idf(word 1) | tfidf(word 2) | … | … | tfidf(word n) |
| Document 2 | tf-idf(word 1) | tfidf(word 2) | … | … | tfidf(word n) |
| … | … | … | … | … | … |
| … | … | … | … | … | … |
| Document n | tf-idf(word 1) | tfidf(word 2) | … | … | tfidf(word n) |
It’s quite important to represent it as sparse matrix as it is otherwise quite bothersome to such a large matrix. Furthermore, it is largely filled with 0’s.
Then we can build a classifier based on the naive bayes framework.
$$ P(y \mid x_1, \dots, x_n) \propto P(y) \prod_{i=1}^{n} P(x_i \mid y) $$ $$ \Downarrow $$ $$ \hat{y} = \argmax_y P(y) \prod_{i=1}^{n} P(x_i \mid y) $$
where
$$ P(x_{i}|y) = \hat{\theta_{yi}} = \frac{N_{yi} + \alpha}{N_{y} + \alpha n} $$
Evaluation
We can examine how the different methods stack up against each other
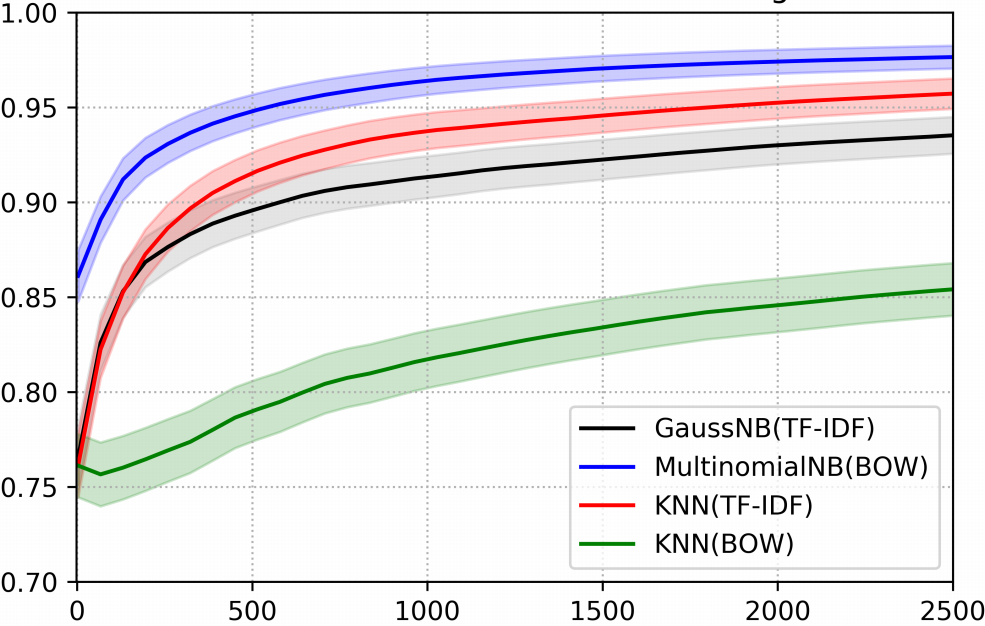
Accuracy of each method, including a few other baseline methods some of which use a simpler word vectorisation method, bag-of-words, of counting
So, we can build a relatively simple classifier that can obtain a >95% accuracy.
